Social Mobility Project
Notes after the December 1999 meeting
First let me thank you all for writing papers and presenting them. In the light of what we heard over the two and a half days of the meeting I am very optimistic that this will prove to be an important and interesting project. In what follows I will try to summarize our discussion of Saturday morning, but I will begin by putting up-front some things that require immediate action.
Issues for immediate attention Top News Home
Issues for immediate attention
Specific people:
1. We agreed to circulate macros to be provided by the following people:
Louis Andre Vallet: LEM macros for Unidiff and for unidiff with other effects in the model
Mike Hout: STATA macros for the same and also a macro/ description of how to compute the SHD shift parameters (though these can be computed as the difference between the destination class marginal parameter and the corresponding origin class parameter: i.e. 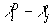 (see The Constant Flux pp.204 onwards)
(see The Constant Flux pp.204 onwards)
If anyone else wants to contribute macros or comments please do so.
2. Walter Muller: a note on the CASMIN educational categories.
Meir Yaish has now set up the project web site so please send the above to him with a copy to me. Meir will post all this material on the web site.
General (questions to everyone)
- Later in this document you will find a draft of the codebook for the variables that will go into the combined analysis. If you have any ideas, problems, misgivings etc. about this please let me know. Also, if there are specific variables that would need to be taken into account in any analysis involving your country (such as race in the USA or perhaps region in Italy) please let me know.
- I suggested that the analysis of the combined data set might best be done by a smaller group. Can you please let me know whether or not you want to be part of this group?
- Robert Erikson asked whether anyone could think of an ordinal test of change over time in the unidiff beta coefficients. If anyone has any ideas please contact me or him.
I would be very grateful if you could reply to these questions (with the exception of 3, which might require a bit more thought!) before December 17th.
Timetable Top News Home
Timetable
The following was agreed:
Second drafts of the country papers to me by the end of September 2000. At the same time send the draft and all background but unreported analyses to your discussant. We will meet in early December 2000 but the format of the meeting will be that each paper will be presented and discussed by the discussant (so the assumption is that everyone will have read all the papers before the meeting). I hope too that we will be in a position to compare some of the results of the combined analysis with the country specific results. The discussants for each country are
Israel: Chris Whelan/ Richard Layte
Ireland: Louis Andre Vallet
Britain: Kristen Ringdal
USA: Peter Robert/ Erzsebet Bukodi
Norway: John Goldthorpe/ Colin Mills
Hungary: Mike Hout
Poland: Robert Erikson/ Jan Jonsson
Germany: Bogdan Mach
Italy: Walter Mueller
France: Meir Yaish
Sweden: Tony Schizzerotto/ Maurizio Pisati
Timetable for the combined data set:
I hope to circulate the proper codebook in early January, so I would be very pleased if you could start sending me the data as soon as you can after that. I know that this is easier for some people than others, but even if we had data for 7 or 8 countries quite quickly this would allow us to make a start on the analysis.
I will not circulate the data to anyone (and certainly will not put into the public domain) without written permission from you.
Further point: many of us will be at Libourne in May, so maybe we could have a short meeting to gauge progress at that time. It may be that some of the Florence papers will be given at that meeting as well.
I will contact a publisher in the New Year to see if they are interested in publishing a book with probably 14 chapters (11 country chapters; methodological chapter; introduction; comparative analysis chapter).
Country Papers Top News Home
Country papers
We came to an agreement that because, in this project, we will have a combined data set, there was less need for uniformity in the country papers than was the case in, say, the Shavit and Mueller book. However, each country chapter should include the following:
A data appendix
Inflow and outflow tables for men and women for the start year of the data series and for the final year (which I was calling t(0) and t(1))
Discussion of changes over the period in the class structure (possibly drawing on other data sources such as censuses)
Figures relating to absolute mobility and changes in this over time: total mobility, upward and downward mobility, vertical mobility (for a model see The Constant Flux, p. 195).
Fit the CnSF and Unidiff models to the data
For the chosen explanatory model report the structural shift parameters as presented in Sobel, Hout and Duncan AJS 1985.
In the case of women's mobility, an analysis that focuses only on women currently in a job.
To recap: the basic aim of these country papers is to undertake separate analyses for men and women and to
Describe the change over the period t(0) to t(1)
Describe the situation at t(1)
Explain change over time (or its absence).
The explanatory part of the paper can use any model you like (Core, SAT, AHP etc etc) and the explanation itself might, for instance, invoke
Economic factors
Institutional factors
Demographic factors
Changing selection effects
Technical causes (such as declining response rates)
and so on. Explanation is a big part of the country chapters since, inter alia, it will provide some clues as to what to look for in the combined analysis.
Codebook Top News Home
Draft codebook for combined data set
It was agreed that the combined data set would now comprise not simply a data set for t(0) and t(1) but the complete sets of data for each country (if this is feasible).
The available data (which I would like to go into the data set) are as follows:
Annual data from USA, Germany, Sweden and Great Britain
Three data sets from Norway, France, Hungary and Ireland
Tow data sets from Italy, Poland and Israel
Age range for data: 20-69 years
Mike Hout suggested that I circulate a codebook and that everyone should then provide their data according to the codebook specifications. That would be excellent, but there are two points to make: first, this is a draft of the codebook, so comments would be welcome. Secondly, if anyone has problems providing the data in the codebook specifications, let me know. Marta Fraile and Asuncion Soro Bonmati can recode your data into the codebook spec. if necessary.
Variables:
1.Country id: codes as follows:
- Germany
- France
- Italy
- Ireland
- Great Britain
- Sweden
- Norway
- Poland
- Hungary
- Israel
- USA
2. Person id
3. Weighting variable (if no weights needed this should be a vector of 1s)
4. Father's class (when respondent was aged around 14 if different measures are available)
Coded according to the EGP 11 class schema (see Table 2.1 of The Constant Flux) or as close as possible:
- I Higher grade professionals etc.
- II Lower grade professionals etc.
- IIIa Routine non-manual, higher grade
- IIIb Routine non-manual, lower grade
- IVa Small proprietors with employees
- IVb Small proprietors without employees
- IVc Farmers
- V Lower grade technicians
- VI Skilled manual workers
- VIIa Semi- and unskilled manual, non-agricultural
- VIIb Semi- and unskilled manual, agricultural
- Father not present
Plus codes for missing etc.
5. Mother's class (11 Category EGP)
6. Respondent's current or most recent class (11 Category EGP)
7. Spouse's current or most recent class (11 Category EGP)
These three coded in same way as 4.
- Father's education (CASMIN categories)
9. Mother's education (CASMIN categories)
10. Respondent's Education (CASMIN categories)
11. Spouse's Education (CASMIN categories)
These four variables to be coded to the expanded 10 category CASMIN educational categories (WM to provide note on this)
12. Father's years of education
13. Mother's education
- Respondent's Education
15. Spouse's Education
For these four variables, if years are not measured directly, impute years using the average number of years in education required to obtain the highest educational qualification that each possesses.
16. Respondent's employment status
- Working f/t
- Working p/t
- Unemployed (ILO definition)
- Looking for 1st job
- Student
- Military
- Unpaid work in the home ('housewife')
- Retired
- Permanently sick/ disabled
- Otherwise Not in Labour Force
17. Length of time (in months) respondent has been in current employment status
18. Length of time (in months) since end of respondent's last job
In this case respondents who were currently working would be coded '0'.
19. Spouse or cohabiting partner's employment status
- Working f/t
- Working p/t
3. Not working
20. Respondent's age (in years and months)
21. Respondent's sex
22. Respondent's marital status
- Married
- Cohabiting
- Never married
- Divorced and currently not married
- Separated (i.e. married but permanently not living with spouse)
23. Age of youngest coresident child (in years)
24. (onwards) Country specific variables (if any)
Richard Breen
December 6, 1999
Top News Home